简介
机器阅读理解是指让计算机能够阅读文本,随后让计算机解答与文中信息相关系的问题.斯坦福大学自然语言计算组发布SQuAD数据集,微软亚研R-Net是首个在某些指标中接近人类的深度学习模型.本篇文章主要叙述的是机器阅读理解中的R-Net神经网络.
机器阅读理解问题描述
文中每个样例大致由一个三元组构成(包含有文章Passage,相应问题Query以及对应答案Answer),输入是一个文章和相应问题,输出是一个答案Answer,三元组均使用(P,Q,A)表示.
R-Net 模型结构图
R-Net模型结构图如下所示
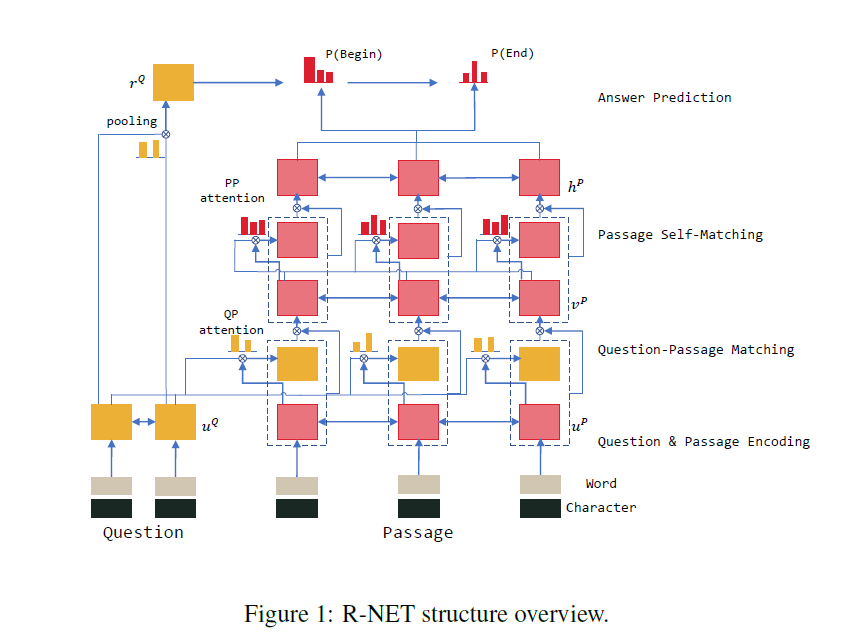
原理介绍
R-Net模型一共分为四个步骤,分别为
- Question and Passage Encoder(问题和文章的编码器)
- Gated Attention-Based Recurrent Networks(门注意力基础循环神经网络)
- Self-Matching Attention (自匹配注意力网络)
- Output layer (输出层)
1. Question and Passage Encoder(问题和文章的编码器)
第一层表示学习过程,R-Net神经网络中输入是Glove+CharEmbedding.第一种是将文章P和问题Q中的单词替换为Glove词向量中的数据$P=\left{e_{t}^{P}\right}{t=1}^{n}$,$Q=\left{e{t}^{Q}\right}{t=1}^{m}$,第二种是charEmbedding:$P{c}=\left{e_{t}^{P}\right}{t=1}^{n}$,$Q{c}=\left{e_{t}^{Q}\right}_{t=1}^{m}$.最终将文章P以及问题Q通过BiRNN神经网络,这里使用的是BiGRU网络.
\[u_{t}^{Q}=BiRNN_{Q}(u_{t-1}^{Q},[e_{t}^{Q},c_{t}^{Q}])\] \[u_{t}^{P}=BiRNN_{Q}(u_{t-1}^{P},[e_{t}^{P},c_{t}^{P}])\]2. Gated Attention-Based Recurrent Networks(门注意力基础循环神经网络)
从上一层神经网络可以得到$u_{t}^{Q}$以及$u_{t}^{P}$,在这一层神经网路试图将$u_{t}^{Q}$进行attention加权融入到$u_{t}^{P}$中,得到问题Q的注意力下的文章语义理解向量
\[v_{t}^{P}=RNN(v_{t-1}^{P},c_{t})\]其中$c_{t}=att(u^{Q},[u_{t}^{P},v_{t-1}^{P}])$是一个对问题Q的attention-pooling加权.具体的形式如下所示
\[s_{j}^{t}=v^{T}\tanh(W_{u}^{Q}u_{j}^{Q}+W_{u}^{P}u_{t}^{Q}+W_{v}^{P}v_{t-1}^{P})\] \[a_{i}^{t}=\exp(s_{i}^{t})/\sum\limits_{j=1}^{m}\exp(s_{j}^{t})\] \[c_{t}=\sum\limits_{i=1}^{m}a_{i}^{t}u_{i}^{Q}\]R-Net又基于Match-LSTM的基础上对以上方法提出一些以下的改进方法,第一点是将$c_{t}$和$u_{t}^{P}$并联为$[c_{t},u_{t}^{P}]$加入RNN中,即
\[v_{t}^{P}=RNN(v_{t-1}^{P},[c_{t},u_{t}^{P}])\]第二点又在$[c_{t},u_{t}^{P}]$上面加入门控制方式,为了更好地抽取和文章有关问题的信息,即加入的以下的方法
\[g_{t}=\sigma(W_{g}[u_{t}^{P},c_{t}])\] \[[u_{t}^{P},c_{t}]^{*}=g_{t}\odot[u_{t}^{P},c_{t}]\]3. Self-Matching Attention (自匹配注意力网络)
自匹配的方式充分借鉴了Attention is all you need中的自注意力思想,在模型效果提升中起了很大的作用,而且这个方法也易于实现.
\[h_{t}^{P}=BiRNN(h_{t-1}^{P},[c_{t},v_{t}^{P}])\]其中,$c_{t}=att(v^{P},v_{t}^{P})$是基于当前单词下的整篇文章的语义
\[s_{j}^{t}=v^{T}\tanh(W_{v}^{P}v_{j}^{P}+W_{v}^{\hat{P}}v_{t}^{P})\] \[a_{i}^{t}=\exp(s_{i}^{t})/\sum\limits_{j=1}^{n}\exp(s_{j}^{t})\] \[c_{t}=\sum\limits_{i=1}^{n}a_{i}^{t}v_{i}^{P}\]4. Output layer (输出层)
R-Net模型输出的是文章中的起始位置,在这一过程中借鉴了pointer-Network的思想,R-Net模型先计算得到开始位置在文章中的分布$p_{1}$,再利用这一分布对整篇文章进行加权作为输入得到终止位置在文章中的分布$p_{2}$.所以这其实是一个seq2seq的过程,只不过最终得到的seq中只有两项,即起始位置$p_{1}$和终止位置$p_{2}$.对于一个seq2seq过程,R-Net使用对问题$u_{t}^{Q}$进行attention-pooling得到的$r^{Q}$作为起始键.
\[s_{j}=v^{T}\tanh(W_{u}^{Q}u_{j}^{Q}+W_{v}^{Q}v_{r}^{Q})\] \[a_{i}^{t}=\exp(s_{i}^{t})/\sum\limits_{j=1}^{n}\exp(s_{j}^{t})\] \[r^{Q}=\sum\limits_{i=1}^{n}a_{i}u_{i}^{Q}\]其中这个seq2seq的循环结构为
\[h_{t}^{q}=RNN(h_{t-1}^{a},c_{t})\]$c_{t}$依然是对文章的attention-pooling得到的结果:
\[s_{j}=v^{T}\tanh(W_{u}^{P}u_{j}^{P}+W_{h}^{a}h_{t-1}^{a})\] \[a_{i}^{t}=\exp(s_{i}^{t})/\sum\limits_{j=1}^{n}\exp(s_{j}^{t})\] \[c_{t}=\sum\limits_{i=1}^{n}a_{i}^{t}h_{i}^{P}\]通过以上RNN循环单元两次可以得到两个权重分布,我们可以通过下面这种方式从中得到答案的其实位置
\[p^{t}=\arg\max\left\{a_{1}^{t},\dots,a_{n}^{t}\right\}\]通过得到两个分布表示$p_{1},p_{2}$,这样就会得到一个联合分布,在计算中可以表示为一个矩阵,然而由于开始位置永远在终止位置之前,所以我们的选择区域始终在矩阵对角线的左上半部分。又因为答案长度有一定范围,我们可以设置答案的最大长度,所以最后的训责区域知识一个若当标准型矩阵的.
文档信息
- 本文作者:MobtgZhang
- 本文链接:https://mobtgzhang.github.io/2021/04/29/RNet-Machine-ReadingComprehensive/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)